
വലിയ ഭാഷാ മോഡലുകളുടെ (LLMs) അനുമാന വേഗത ത്വരിതപ്പെടുത്തുന്നതിനും ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിനും ലക്ഷ്യമിട്ടുള്ള ഒരു സഹകരണം ആപ്പിളും എൻവിഡിയയും അടുത്തിടെ പ്രഖ്യാപിച്ചു.
പരമ്പരാഗത ഓട്ടോറിഗ്രസീവ് എൽഎൽഎം അനുമാനത്തിന്റെ കാര്യക്ഷമതയില്ലായ്മയും പരിമിതമായ മെമ്മറി ബാൻഡ്വിഡ്ത്തും പരിഹരിക്കുന്നതിനായി, ആപ്പിളിന്റെ മെഷീൻ ലേണിംഗ് ഗവേഷകർ 2024 ന്റെ തുടക്കത്തിൽ "റീഡ്രാഫ്റ്റർ" (ആവർത്തന ഡ്രാഫ്റ്റ് മോഡൽ) എന്ന ഒരു അനുമാന ഡീകോഡിംഗ് സാങ്കേതികത പുറത്തിറക്കി ഓപ്പൺ സോഴ്സ് ചെയ്തു.
നിലവിൽ, എൻവിഡിയയുടെ സ്കേലബിൾ അനുമാന പരിഹാരമായ "TensorRT-LLM"-ൽ ReDrafter സംയോജിപ്പിച്ചിരിക്കുന്നു. ഈ പരിഹാരം "TensorRT" ഡീപ് ലേണിംഗ് കംപൈലർ ഫ്രെയിംവർക്കിനെ അടിസ്ഥാനമാക്കിയുള്ള ഒരു ഓപ്പൺ സോഴ്സ് ലൈബ്രറിയാണ്, ഇത് LLM അനുമാനം ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിനും "Medusa" പോലുള്ള ഊഹക്കച്ചവട ഡീകോഡിംഗ് രീതികളെ പിന്തുണയ്ക്കുന്നതിനുമായി പ്രത്യേകം രൂപകൽപ്പന ചെയ്തിരിക്കുന്നു.
എന്നിരുന്നാലും, ReDrafter-ന്റെ അൽഗോരിതങ്ങൾ മുമ്പ് ഉപയോഗിക്കാത്ത ഓപ്പറേറ്റർമാരെ ഉപയോഗിക്കുന്നതിനാൽ, Nvidia പുതിയ ഓപ്പറേറ്റർമാരെ ചേർക്കുകയോ നിലവിലുള്ളവയെ പൊതുവായതാക്കുകയോ ചെയ്തിട്ടുണ്ട്, ഇത് സങ്കീർണ്ണമായ മോഡലുകളുമായും ഡീകോഡിംഗ് രീതികളുമായും പൊരുത്തപ്പെടാനുള്ള TensorRT-LLM-ന്റെ കഴിവ് ഗണ്യമായി വർദ്ധിപ്പിക്കുന്നു.
മൂന്ന് പ്രധാന സാങ്കേതികവിദ്യകളിലൂടെ വലിയ ഭാഷാ മോഡലുകളുടെ (LLM) അനുമാന പ്രക്രിയയെ ReDrafter ത്വരിതപ്പെടുത്തുന്നുവെന്ന് റിപ്പോർട്ട് ചെയ്യപ്പെടുന്നു:
- ആർഎൻഎൻ ഡ്രാഫ്റ്റ് മോഡൽ
- ഡൈനാമിക് ട്രീ അറ്റൻഷൻ അൽഗോരിതം
- വിജ്ഞാന വാറ്റിയെടുക്കൽ പരിശീലനം
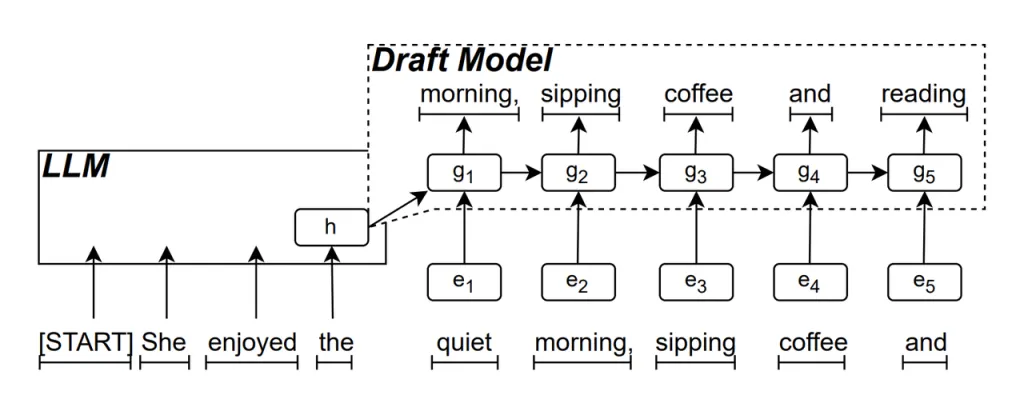
ആർഎൻഎൻ ഡ്രാഫ്റ്റ് മോഡൽ റീഡ്രാഫ്റ്ററിന്റെ പ്രധാന ഭാഗമാണ്. എൽഎൽഎമ്മിന്റെ മറഞ്ഞിരിക്കുന്ന അവസ്ഥകളെ അടിസ്ഥാനമാക്കി അടുത്ത സാധ്യമായ പദ ശ്രേണി പ്രവചിക്കാൻ ഇത് ഒരു ആവർത്തന ന്യൂറൽ നെറ്റ്വർക്ക് (ആർഎൻഎൻ) ഉപയോഗിക്കുന്നു. ഇത് താൽക്കാലിക ആശ്രിതത്വങ്ങൾ പിടിച്ചെടുക്കുകയും പ്രവചന കൃത്യത മെച്ചപ്പെടുത്തുകയും ചെയ്യുന്നു.
ഈ മോഡൽ പ്രവർത്തിക്കുന്ന രീതി ഇപ്രകാരമാണ്: LLM ടെക്സ്റ്റ് സൃഷ്ടിക്കുമ്പോൾ, അത് ആദ്യം ഒരു ഇനീഷ്യൽ വേഡ് സൃഷ്ടിക്കുന്നു, തുടർന്ന് RNN ഡ്രാഫ്റ്റ് മോഡൽ ഈ വാക്കും അവസാന ലെയറിന്റെ LLM-ന്റെ മറഞ്ഞിരിക്കുന്ന അവസ്ഥയും ഇൻപുട്ടായി ഉപയോഗിച്ച് ബീം സെർച്ച് നടത്തുന്നു, ഇത് ഒന്നിലധികം കാൻഡിഡേറ്റ് വേഡ് സീക്വൻസുകൾ സൃഷ്ടിക്കുന്നു.
ഒരു സമയം ഒരു വാക്ക് സൃഷ്ടിക്കുന്ന പരമ്പരാഗത ഓട്ടോറിഗ്രസീവ് എൽഎൽഎമ്മുകളിൽ നിന്ന് വ്യത്യസ്തമായി, ആർഎൻഎൻ ഡ്രാഫ്റ്റ് മോഡലിന്റെ പ്രവചനങ്ങളിലൂടെ ഓരോ ഡീകോഡിംഗ് ഘട്ടത്തിലും റീഡ്രാഫ്റ്ററിന് ഒന്നിലധികം വാക്കുകൾ സൃഷ്ടിക്കാൻ കഴിയും, ഇത് മൂല്യനിർണ്ണയത്തിനായി എൽഎൽഎമ്മിനെ വിളിക്കേണ്ടതിന്റെ എണ്ണം ഗണ്യമായി കുറയ്ക്കുകയും അതുവഴി മൊത്തത്തിലുള്ള അനുമാന വേഗത മെച്ചപ്പെടുത്തുകയും ചെയ്യുന്നു.
ഡൈനാമിക് ട്രീ അറ്റൻഷൻ അൽഗോരിതം ബീം തിരയൽ ഫലങ്ങൾ ഒപ്റ്റിമൈസ് ചെയ്യുന്ന ഒരു അൽഗോരിതം ആണ്.
ബീം തിരയൽ പ്രക്രിയയിൽ, ഒന്നിലധികം കാൻഡിഡേറ്റ് സീക്വൻസുകൾ സൃഷ്ടിക്കപ്പെടുന്നു, അവയ്ക്ക് പലപ്പോഴും ഒരേ തുടക്കമുണ്ട്. ഡൈനാമിക് ട്രീ അറ്റൻഷൻ അൽഗോരിതം ഈ പൊതുവായ തുടക്കങ്ങളെ തിരിച്ചറിയുകയും സാധൂകരിക്കേണ്ട പദങ്ങളിൽ നിന്ന് അവയെ നീക്കം ചെയ്യുകയും ചെയ്യുന്നു, ഇത് LLM പ്രോസസ്സ് ചെയ്യേണ്ട ഡാറ്റയുടെ അളവ് കുറയ്ക്കുന്നു.
ചില സന്ദർഭങ്ങളിൽ, ഈ അൽഗോരിതം സാധൂകരിക്കേണ്ട പദങ്ങളുടെ എണ്ണം 30% മുതൽ 60% വരെ കുറയ്ക്കാൻ സഹായിക്കും. അതായത്, ഡൈനാമിക് ട്രീ അറ്റൻഷൻ അൽഗോരിതം ഉപയോഗിച്ച്, റീഡ്രാഫ്റ്ററിന് കമ്പ്യൂട്ടേഷണൽ റിസോഴ്സുകൾ കൂടുതൽ കാര്യക്ഷമമായി ഉപയോഗിക്കാൻ കഴിയും, ഇത് അനുമാന വേഗത കൂടുതൽ മെച്ചപ്പെടുത്തുന്നു.
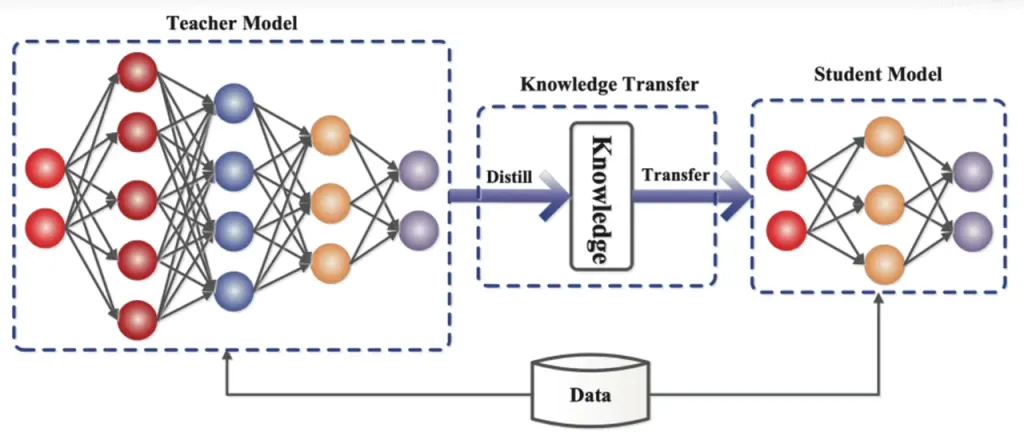
അറിവ് വാറ്റിയെടുക്കൽ ഒരു വലിയ, സങ്കീർണ്ണമായ മോഡലിൽ (ടീച്ചർ മോഡൽ) നിന്ന് ചെറുതും ലളിതവുമായ ഒരു മോഡലിലേക്ക് (സ്റ്റുഡന്റ് മോഡൽ) അറിവ് കൈമാറുന്ന ഒരു മോഡൽ കംപ്രഷൻ ടെക്നിക്കാണ്. റീഡ്രാഫ്റ്ററിൽ, ആർഎൻഎൻ ഡ്രാഫ്റ്റ് മോഡൽ വിദ്യാർത്ഥി മോഡലായി പ്രവർത്തിക്കുന്നു, എൽഎൽഎമ്മിൽ (ടീച്ചർ മോഡൽ) നിന്ന് വിജ്ഞാന വാറ്റിയെടുക്കൽ വഴി പഠിക്കുന്നു.
വിശദമായി പറഞ്ഞാൽ, ഡിസ്റ്റിലേഷൻ പരിശീലന പ്രക്രിയയിൽ, ഒരു വലിയ ഭാഷാ മാതൃക (LLM) അടുത്ത സാധ്യമായ പദങ്ങൾക്കായി "പ്രോബബിലിറ്റി ഡിസ്ട്രിബ്യൂഷനുകളുടെ" ഒരു പരമ്പര നൽകുന്നു. ഒരു റിക്കറന്റ് ന്യൂറൽ നെറ്റ്വർക്ക് (RNN) ഡ്രാഫ്റ്റ് മോഡലിനെ പരിശീലിപ്പിക്കുന്നതിന് ഡെവലപ്പർമാർ ഈ പ്രോബബിലിറ്റി ഡിസ്ട്രിബ്യൂഷൻ ഡാറ്റ ഉപയോഗിക്കുന്നു, തുടർന്ന് രണ്ട് മോഡലുകളുടെയും പ്രോബബിലിറ്റി ഡിസ്ട്രിബ്യൂഷനുകൾ തമ്മിലുള്ള വ്യത്യാസം കണക്കാക്കുന്നു, ഒപ്റ്റിമൈസേഷൻ അൽഗോരിതങ്ങൾ വഴി ഈ വ്യത്യാസം കുറയ്ക്കുന്നു.
ഈ പ്രക്രിയയ്ക്കിടയിൽ, ആർഎൻഎൻ ഡ്രാഫ്റ്റ് മോഡൽ എൽഎൽഎമ്മിന്റെ പ്രോബബിലിറ്റി പ്രവചന പാറ്റേണുകൾ തുടർച്ചയായി പഠിക്കുന്നു, ഇത് പ്രായോഗിക പ്രയോഗങ്ങളിൽ എൽഎൽഎമ്മിന് സമാനമായ വാചകം സൃഷ്ടിക്കാൻ പ്രാപ്തമാക്കുന്നു.
വിജ്ഞാന വാറ്റിയെടുക്കൽ പരിശീലനത്തിലൂടെ, RNN ഡ്രാഫ്റ്റ് മോഡൽ ഭാഷയുടെ നിയമങ്ങളും പാറ്റേണുകളും നന്നായി പിടിച്ചെടുക്കുന്നു, അതുവഴി LLM-ന്റെ ഔട്ട്പുട്ട് കൂടുതൽ കൃത്യമായി പ്രവചിക്കുന്നു. ചെറിയ വലിപ്പവും കുറഞ്ഞ കമ്പ്യൂട്ടേഷണൽ ചെലവും കാരണം, പരിമിതമായ ഹാർഡ്വെയർ സാഹചര്യങ്ങളിൽ ReDrafter-ന്റെ മൊത്തത്തിലുള്ള പ്രകടനം ഇത് ഗണ്യമായി മെച്ചപ്പെടുത്തുന്നു.
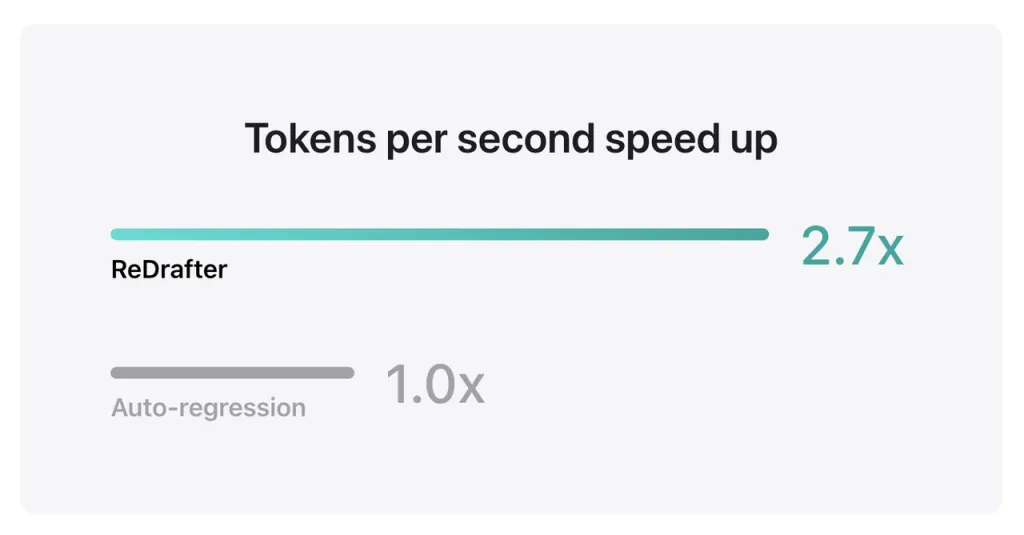
ആപ്പിളിന്റെ ബെഞ്ച്മാർക്ക് ഫലങ്ങൾ കാണിക്കുന്നത്, NVIDIA H100 GPU-യിൽ ReDrafter-ന്റെ TensorRT-LLM-മായി സംയോജിപ്പിച്ച കോടിക്കണക്കിന് പാരാമീറ്ററുകളുള്ള പ്രൊഡക്ഷൻ മോഡൽ ഉപയോഗിക്കുമ്പോൾ, Greedy Decoding വഴി സെക്കൻഡിൽ സൃഷ്ടിക്കപ്പെടുന്ന ടോക്കണുകളുടെ എണ്ണം 2.7 മടങ്ങ് വർദ്ധിച്ചു എന്നാണ്.
കൂടാതെ, ആപ്പിളിന്റെ സ്വന്തം M2 അൾട്രാ മെറ്റൽ ജിപിയുവിൽ, റീഡ്രാഫ്റ്റർ 2.3 മടങ്ങ് അനുമാന വേഗത മെച്ചപ്പെടുത്തി. ആപ്പിളിന്റെ ഗവേഷകർ പ്രസ്താവിച്ചു, "പ്രൊഡക്ഷൻ ആപ്ലിക്കേഷനുകൾ പ്രവർത്തിപ്പിക്കാൻ എൽഎൽഎമ്മുകൾ കൂടുതലായി ഉപയോഗിക്കുന്നതിനാൽ, അനുമാന കാര്യക്ഷമത മെച്ചപ്പെടുത്തുന്നത് കമ്പ്യൂട്ടേഷണൽ ചെലവുകളെ ബാധിക്കുകയും ഉപയോക്തൃ-അവസാന ലേറ്റൻസി കുറയ്ക്കുകയും ചെയ്യും."
ഔട്ട്പുട്ട് ഗുണനിലവാരം നിലനിർത്തിക്കൊണ്ട് തന്നെ, ReDrafter GPU ഉറവിടങ്ങൾക്കായുള്ള ആവശ്യം കുറയ്ക്കുന്നു, ഇത് റിസോഴ്സ് പരിമിതമായ പരിതസ്ഥിതികളിൽ പോലും LLM-കളെ കാര്യക്ഷമമായി പ്രവർത്തിക്കാൻ അനുവദിക്കുന്നു, ഇത് വിവിധ ഹാർഡ്വെയർ പ്ലാറ്റ്ഫോമുകളിൽ LLM-കൾ ഉപയോഗിക്കുന്നതിനുള്ള പുതിയ സാധ്യതകൾ നൽകുന്നു എന്നത് ശ്രദ്ധിക്കേണ്ടതാണ്.
ആപ്പിൾ ഇതിനകം തന്നെ ഈ സാങ്കേതികവിദ്യ GitHub-ൽ ഓപ്പൺ സോഴ്സ് ചെയ്തിട്ടുണ്ട്, ഭാവിയിൽ, ഇതിൽ നിന്ന് പ്രയോജനം നേടുന്ന കമ്പനികളിൽ NVIDIA മാത്രമല്ല കൂടുതൽ കമ്പനികളും ഉൾപ്പെടും.
ഉറവിടം ഇഫാൻ
നിരാകരണം: മുകളിൽ നൽകിയിരിക്കുന്ന വിവരങ്ങൾ Alibaba.com-ൽ നിന്ന് സ്വതന്ത്രമായി ifanr.com ആണ് നൽകുന്നത്. വിൽപ്പനക്കാരന്റെയും ഉൽപ്പന്നങ്ങളുടെയും ഗുണനിലവാരവും വിശ്വാസ്യതയും സംബന്ധിച്ച് Alibaba.com യാതൊരു പ്രാതിനിധ്യവും വാറന്റിയും നൽകുന്നില്ല. ഉള്ളടക്കത്തിന്റെ പകർപ്പവകാശ ലംഘനങ്ങൾക്കുള്ള ഏതൊരു ബാധ്യതയും Alibaba.com വ്യക്തമായി നിരാകരിക്കുന്നു.



