Recently, Apple and Nvidia announced a collaboration aimed at accelerating and optimizing the inference speed of large language models (LLMs).
To address the inefficiencies and limited memory bandwidth of traditional autoregressive LLM inference, Apple’s machine learning researchers released and open-sourced a speculative decoding technique called “ReDrafter” (Recurrent Draft Model) earlier in 2024.
Currently, ReDrafter has been integrated into Nvidia’s scalable inference solution “TensorRT-LLM.” This solution is an open-source library based on the “TensorRT” deep learning compiler framework, specifically designed to optimize LLM inference and support speculative decoding methods like “Medusa.”
However, since ReDrafter’s algorithms use previously unused operators, Nvidia has added new operators or made existing ones public, significantly enhancing TensorRT-LLM’s ability to adapt to complex models and decoding methods.
It is reported that ReDrafter accelerates the inference process of large language models (LLM) through three key technologies:
- RNN Draft Model
- Dynamic Tree Attention Algorithm
- Knowledge Distillation Training
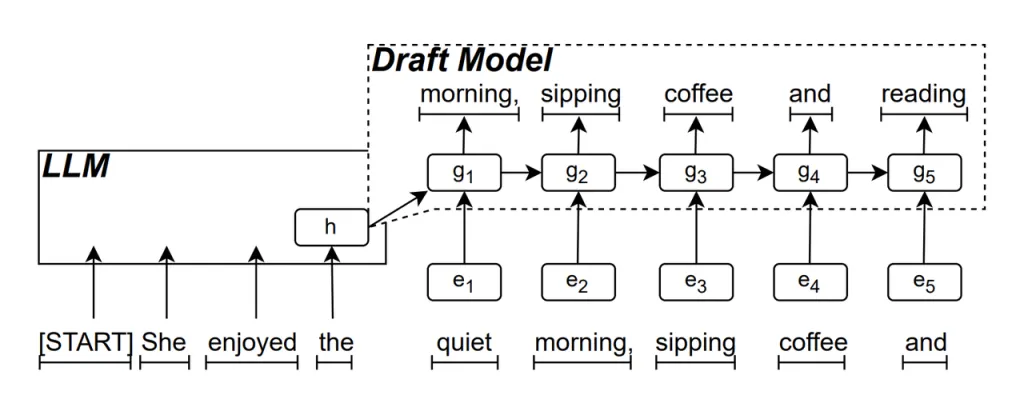
RNN Draft Model is the core part of ReDrafter. It uses a Recurrent Neural Network (RNN) to predict the next possible word sequence based on the hidden states of the LLM. This captures temporal dependencies and improves prediction accuracy.
The way this model works is: when the LLM generates text, it first generates an initial word, then the RNN Draft Model uses this word and the last layer’s hidden state of the LLM as input to perform beam search, generating multiple candidate word sequences.
Unlike traditional autoregressive LLMs that generate one word at a time, ReDrafter can generate multiple words at each decoding step through the predictions of the RNN Draft Model, significantly reducing the number of times the LLM needs to be called for validation, thereby improving overall inference speed.
Dynamic Tree Attention Algorithm is an algorithm that optimizes beam search results.
During the beam search process, multiple candidate sequences are generated, which often have the same beginning. The Dynamic Tree Attention Algorithm identifies these common beginnings and removes them from the words that need to be validated, reducing the amount of data the LLM needs to process.
In some cases, this algorithm can reduce the number of words that need to be validated by 30% to 60%. This means that with the Dynamic Tree Attention Algorithm, ReDrafter can utilize computational resources more efficiently, further improving inference speed.
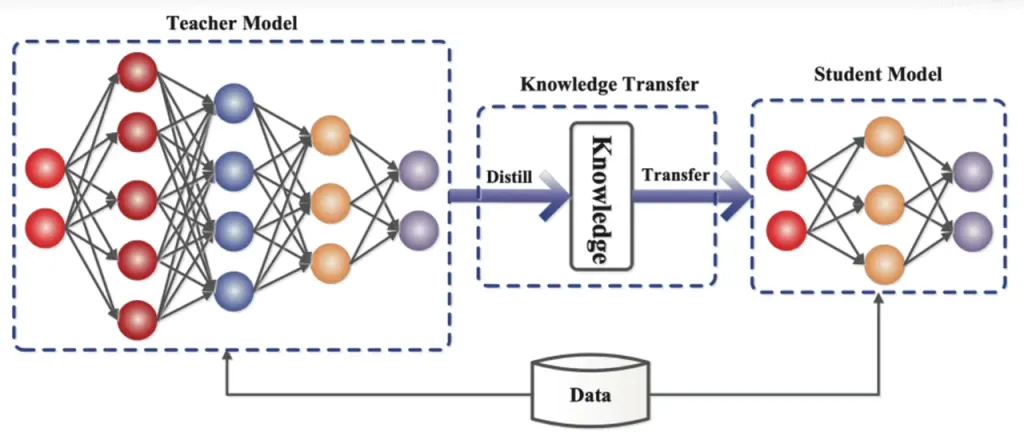
Knowledge Distillation is a model compression technique that transfers the knowledge from a large, complex model (teacher model) to a smaller, simpler model (student model). In ReDrafter, the RNN Draft Model acts as the student model, learning from the LLM (teacher model) through knowledge distillation.
In detail, during the distillation training process, a large language model (LLM) provides a series of “probability distributions” for the next possible words. Developers use this probability distribution data to train a Recurrent Neural Network (RNN) draft model, then calculate the difference between the probability distributions of the two models, and minimize this difference through optimization algorithms.
During this process, the RNN draft model continuously learns the probability prediction patterns of the LLM, enabling it to generate text similar to the LLM in practical applications.
Through knowledge distillation training, the RNN draft model better captures the rules and patterns of language, thus more accurately predicting the LLM’s output. Due to its smaller size and lower computational cost, it significantly improves ReDrafter’s overall performance under limited hardware conditions.
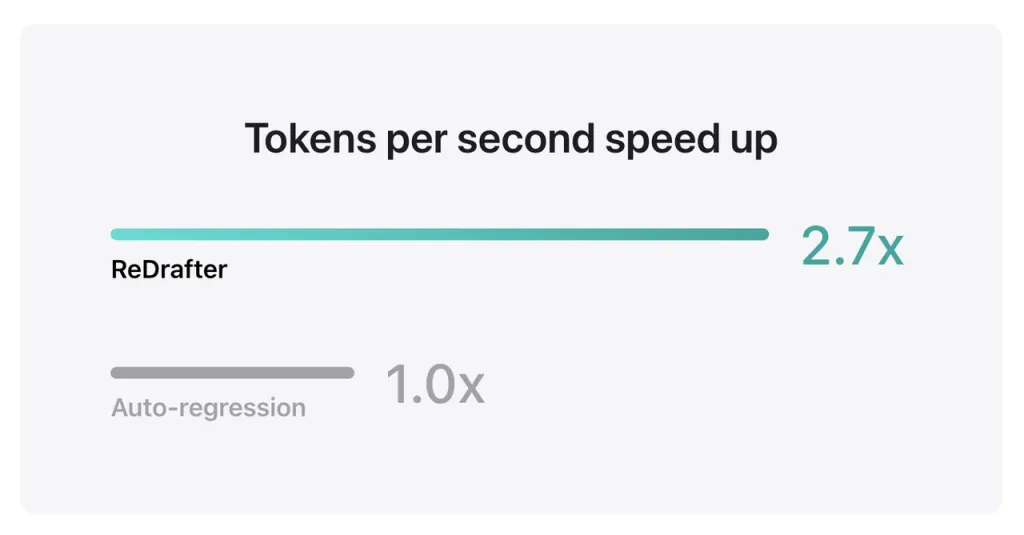
Apple’s benchmark results show that when using the production model with billions of parameters integrated with ReDrafter’s TensorRT-LLM on the NVIDIA H100 GPU, the number of tokens generated per second by Greedy Decoding increased by 2.7 times.
Additionally, on Apple’s own M2 Ultra Metal GPU, ReDrafter achieved a 2.3 times inference speed improvement. Apple’s researchers stated, “As LLMs are increasingly used to drive production applications, improving inference efficiency can impact computational costs and reduce user-end latency.”
It is worth noting that while maintaining output quality, ReDrafter reduces the demand for GPU resources, allowing LLMs to run efficiently even in resource-constrained environments, providing new possibilities for the use of LLMs on various hardware platforms.
Apple has already open-sourced this technology on GitHub, and in the future, companies benefiting from it will likely include more than just NVIDIA.
Source from ifanr
Disclaimer: The information set forth above is provided by ifanr.com, independently of Alibaba.com. Alibaba.com makes no representation and warranties as to the quality and reliability of the seller and products. Alibaba.com expressly disclaims any liability for breaches pertaining to the copyright of content.



